Galileo Elastic Enrichment Cloud (GE2C)
The Galileo Elastic Enrichment Cloud (GE2C) transforms transactional data into enriched concepts. GE2C attains extreme scalability and performance using a containerized, dynamically-allocated compute architecture that performs all transformations on efficient in-memory data structures that are partitioned for scale-out operations.
The “GE2C Build Service” executes python-based “GE2C Data Transformers” using compute resources in AWS Elastic Compute Services. It acquires partitioned data resources from the transactional data model in Redshift via the “GE2C Data Provider”. Enriched results are persisted back to Redshift.
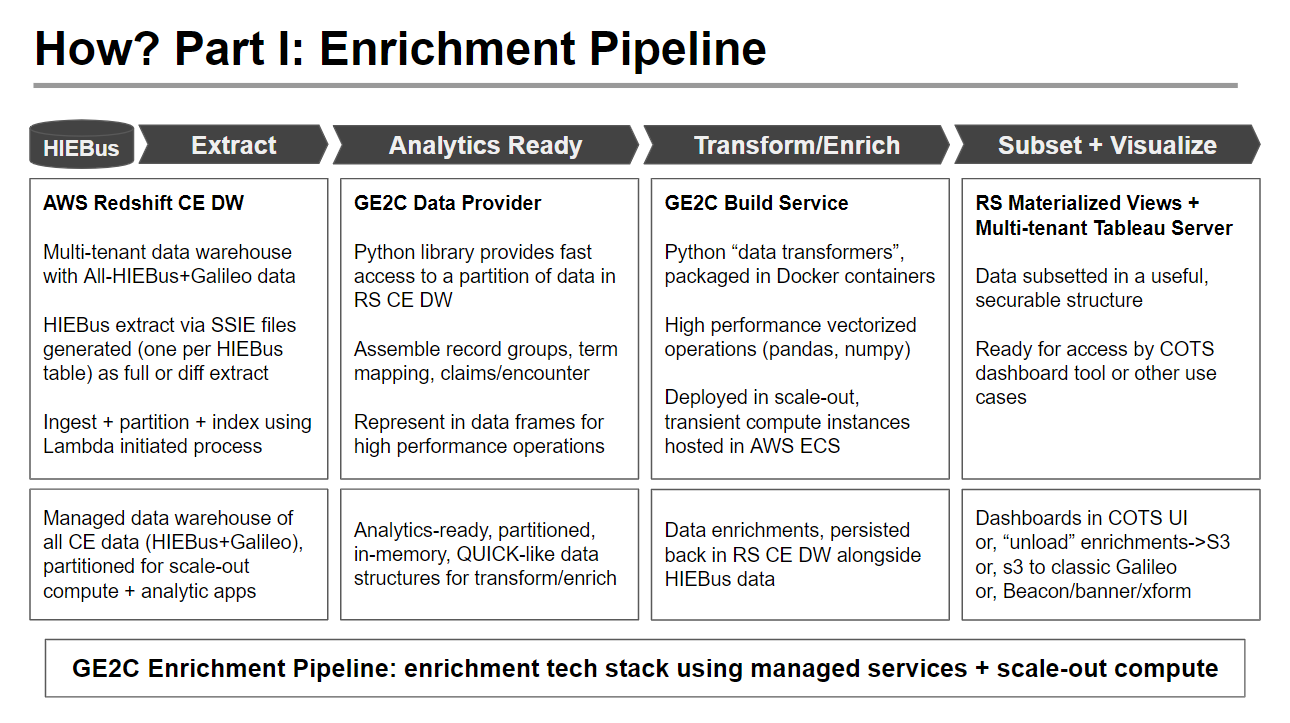
The managed Galileo Build service uses a scale-out processing model that utilizes compute resources that are dynamically allocated in AWS ECS Fargate and only provisioned during the course of a build. The Galileo Build Service runs specified “data transformers”, written in python, by provisioning ECS resources based on container images in AWS ECR that are built to package the python data transformers and the CE-developed libraries required to run them (accessing the Redshift CE Data Warehouse using the GE2C Data Provider).
The managed Galileo Build Service can produce and maintain the enriched data model with less than 24 hour latency at 100M person scale.
This is made possible by:
-
Enrichment operations are performed exclusively using vectorized operations on partitioned (typically on the order of 10k recordgroup blocks) in-memory representations of all data concepts. During each enrichment cycle, all required data is first loaded from Redshift into partitioned memory structures for scale out compute operations.
-
The compute resources (in terms of allocated processors and memory) to support these all-in-memory enrichment operations are very substantial. However, the overall costs of server + licenses (for OS and database) are comparably low because all compute resources for enrichment are allocated dynamically. When enrichment operations are not in progress, no compute resources are allocated. Compute resources are instantiated using containerized images that are customized per tenant/deployment to produce enrichments required for the tenant using enrichment logic that can be customized per tenant.
-
This architecture maintains a strict separation of the compute resources dedicated to persistence (that is, maintaining a copy of HIEBus data and the enrichment results) and to enrichment (actually computing the enrichment results by acquiring data and applying the python data transformers).
This approach is very advantageous as it permits efficient scale-out of the compute process by dynamically allocating enrichment compute resources ONLY when needed and organizing the enrichment operations into relatively small, independent partitions. It is notable that compute resources are allocated in two very different schemes: during “cloud build” compute resources are dynamically allocated using AWS ECS Fargate; during development of the python data transformers, a local developers machine is commonly used to perform the compute on a limited population (up to 10k record groups).